
Whoa, this is wild! I opened a Solana explorer late last night and something clicked. My first impression was speed, raw throughput, and a messy UX though. Initially I thought block explorers were all glue code on top of RPC endpoints, but then I started tracing SOL transactions end-to-end and realized the data shapes and heuristics matter a lot more for analytics pipelines. I’ll be honest — I’ve used dozens of explorers over the years, and when you need transaction provenance, token movement visualizations, or program logs that actually help debug a failed transfer, you quickly separate the tools that are built for humans from those built for dashboards (and those two are not the same thing).
Really, no lie. Sol transactions look trivial on the surface: signatures, accounts, lamports moved. But dig in and you hit inner instructions, CPI (cross-program invocation) trees, and duplicated token transfers that obscure intent. On one hand you can follow a transaction hash and feel satisfied; though actually, if you want to build analytics or fraud detection you need to reconstruct intent across slots and transient accounts. My instinct said the RPC would be enough, but then I started reconciling confirmed vs finalized states and realized that finality semantics matter for reporting.
Hmm, somethin’ felt off. The raw log lines are invaluable, yet they come in inconsistent shape depending on which runtime the program used. Something bothered me about indexing strategies too — naive approaches miss rent-exempt account reuse and subtle token-account reassignments. Initially I favored full archival ingestion, but that quickly became both expensive and overkill for many queries, so I pivoted to selective indexing of program topics and event parsers.
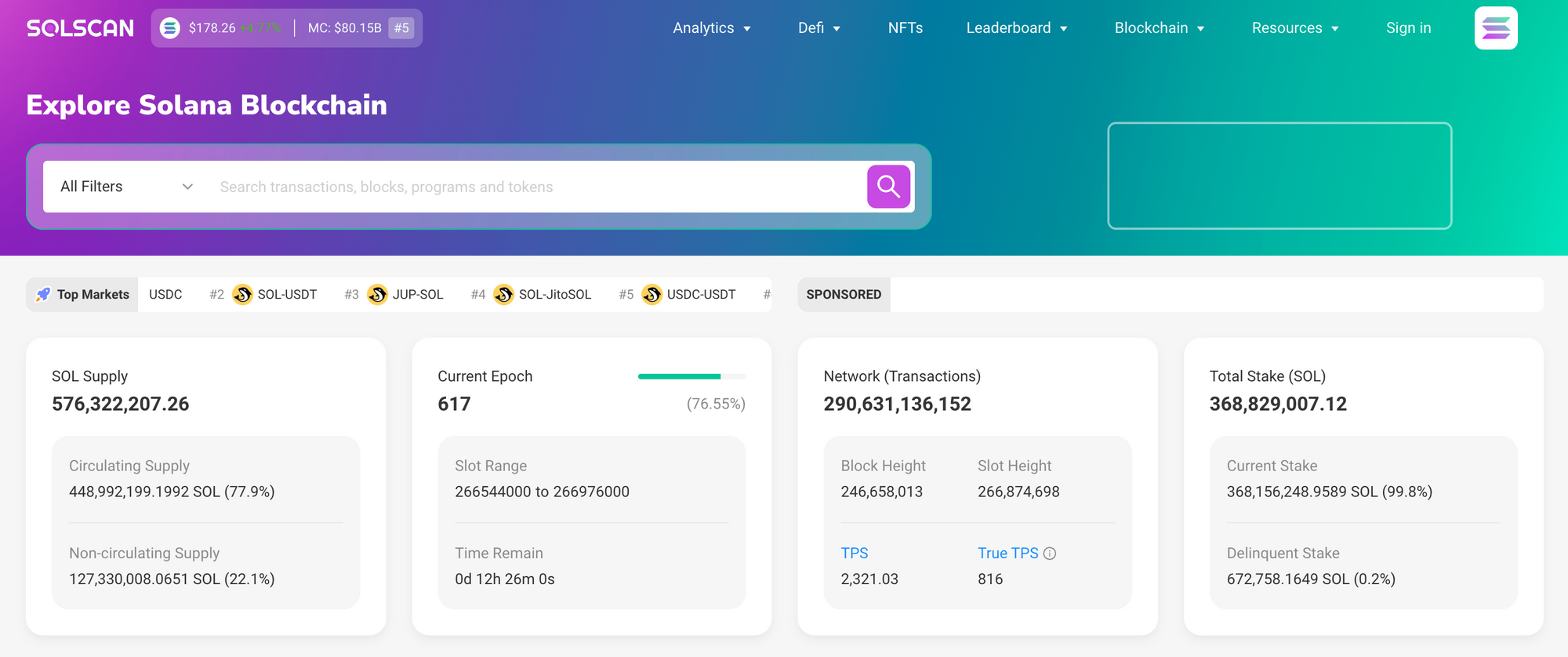
Practical tips and where tools like solscan fit
Whoa, this one actually helps. If you want quick visibility into a SOL transaction, a clean explorer that shows inner instructions, decoded program logs, and token transfer flows saves hours. I’m biased, but I lean toward explorers that let you expand CPI call trees and snapshot account states at pre and post-instruction points because that maps back to how real wallets and DEXs operate. For analytics, combine that with an event-parsing layer (so you can tag swaps, mints, burns) and a simple dedupe of token-mint-pair transfers — otherwise token flows look very very noisy.
Seriously, pay attention to confirmations. Analytics that mix confirmed and finalized data will produce weird temporal artifacts, especially around high-load periods when forks or retries occur. On the engineering side, shamefully many teams under-index program logs, which means when an incident happens you scramble to reprocess slots. A pragmatic approach is to index logs for high-value programs and store canonical signers and pre/post balances for accounts that matter most to your product.
Wow, here’s the deeper bit. When reconstructing provenance you should correlate transaction signatures with block times, inner-instruction sequences, and token metadata updates, because token metadata changes (like updates to a mint) can flip how you interpret historical transfers. Initially I thought a single canonical view per slot would suffice, but in practice you need both slot-level snapshots and event-driven deltas to support queries like “who owned this NFT on this date” or “how much SOL was routed through program X during that hour”.
Hmm, this gets technical quickly. For on-chain analytics, prioritize these three things: reliable ingestion, lightweight decoding, and flexible query models. Reliable ingestion implies handling retries, skipped slots, and RPC inconsistencies; lightweight decoding means parsing only the program logs you care about and emitting normalized events; flexible queries allow both time-series metrics and entity-centric histories. (Oh, and by the way: keep your pipeline observability — logs about your logs — because debugging indexers is its own nightmare.)
Okay, check this out — visualization matters. A transaction graph that collapses trivial lamport dust transfers and highlights program-level state changes makes interpretation faster for humans. I’m not 100% sure every team needs that, but product folks love simplified flows when they’re triaging user disputes. Also, small quality-of-life features like linking directly to the slot, showing pre/post balances inline, and offering a raw JSON toggle are surprisingly appreciated by engineers and legal folks alike.
Whoa, quick note about performance. If you’re running analytics at scale, avoid storing full transaction bodies for every slot unless you absolutely need them; instead store indices and rehydrate transactions on demand from archival nodes. This reduces storage costs and speeds up common queries. On one hand you lose immediate full-text search on all logs, though actually storing bloom-filters or searchable event indices gives you a good middle ground.
Common questions
How do explorers decode inner instructions?
They map program IDs to parsers (some open source, some homegrown) and replay instruction data against those parsers to produce structured events; when parsers are missing they fall back to opaque hex, which is less useful for analytics. The best explorers maintain a curated set of decoders and community-sourced schemas to keep coverage high.
What’s the single best improvement for Solana analytics?
Start by normalizing events: token transfers, swaps, mints, burns, and account-creations should be first-class indexed entities. From there, add pre/post state snapshots for a small set of high-value accounts and surface CPI relationships — that combination yields actionable, auditable metrics without drowning in raw RPC logs.